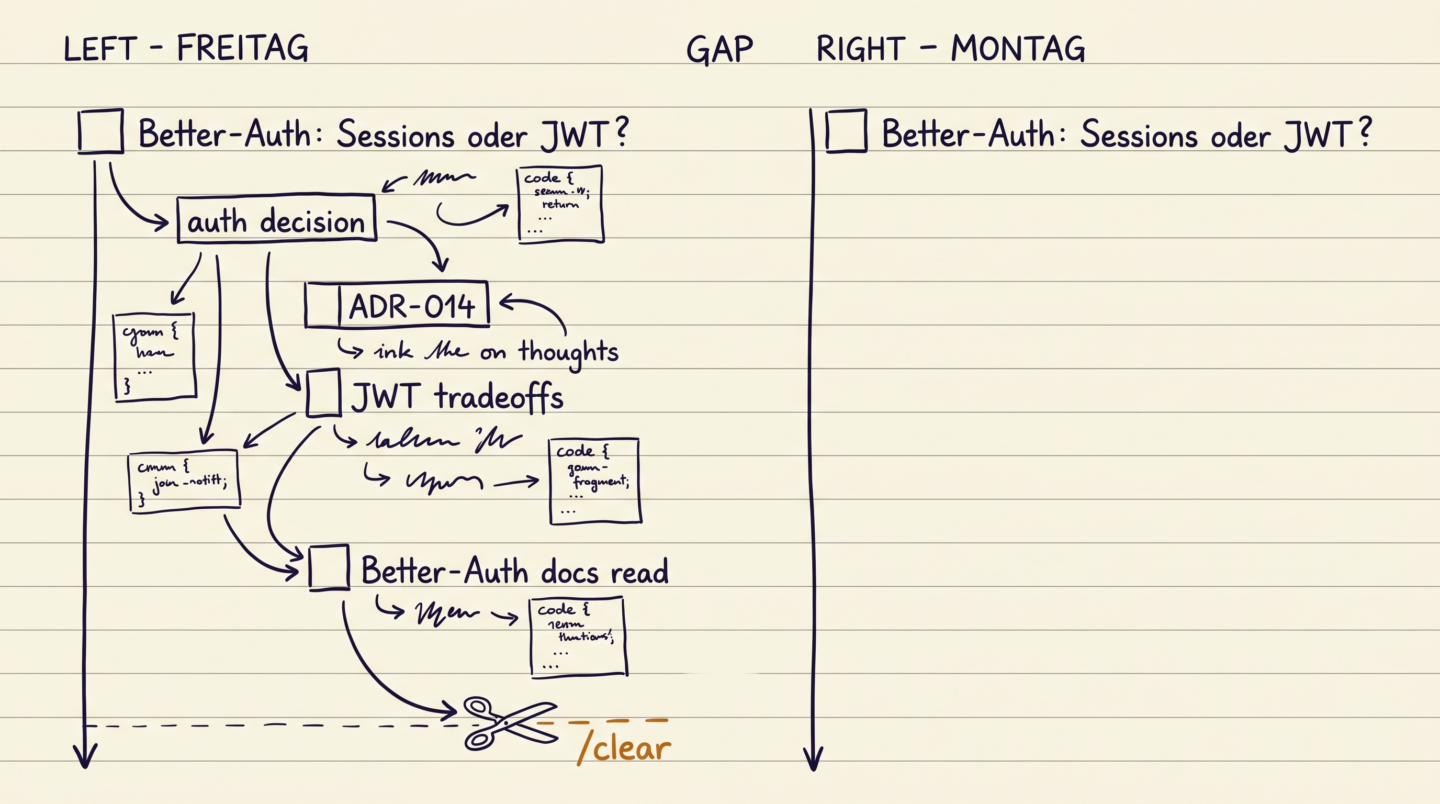
Drei Stunden Sparring über Auth-Architektur am Freitag. Wir kamen zu einer Entscheidung, ich schrieb sie als ADR weg, der Code wurde gemerged. Am Montag fragt der gleiche Agent erneut, ob wir Better-Auth mit Sessions oder JWT machen sollen. Die Entscheidung war im Code, in einer ADR, in einem Chat. Nichts davon hat den /clear überlebt.
Das ist nicht ärgerlich, sondern wie bei einer Demenz, wo man alle paar Minuten das gleiche Gespräch führt.
„Mehr Zeit fürs aufräumen als der Agent dir spart”
Ein Kommentar auf GitHub-Issue #6601 im anthropics/claude-code-Repo trifft den Nerv1:
„He is context damaged from the onset of fresh sessions, the very first response he is broken. You get a bit of the project to progress then spend twice as long repairing.”
Und aus dem r/ExperiencedDevs-Thread über AI-Slop-PRs, User SonOfSpades2:
„Multiple 5k+ line PR’s that should be sub 100 lines. AI hallucinating external services, then mocking out the hallucinated external services.”
Ich kenne beides aus eigener Praxis. Bei meinem SaaS, drei Repos, eine Telefonie-Pipeline, dauerte jeder PR-Review länger als das Entwickeln. Der Agent halluzinierte einen resolve_bucket()-Aufruf der so nie existierte. Er erfand einen Service-Endpoint und mockte ihn gleich mit. Jedes Refactor-PR brachte 5000 Zeilen, weil der Agent das ganze Repo „aufgeräumt” hatte, statt die drei Files zu fassen die ich gemeint hatte.
Mein SaaS soll leichter werden je mehr ich baue. Tatsächlich ist das Gegenteil der Fall und das ist ein Problem.
Seit Jahren wird gepredigt: Agents sind für Greenfield-Projekte super. Frischer Codebase, grüne Wiese, der Agent darf von null bauen. Brownfield ist das andere Extrem: gewachsene Codebase, ADRs die nicht mehr aktuell sind, Tests die Annahmen haben, Architektur die andere Architektur einschränkt. Das ist der Modus in dem fast jeder Production-Code lebt. Genau da fallen die Agents auseinander.
Was ist Compound Engineering
Compound Engineering ist ein Loop aus Plan, Work, Review und Compound, in dem jeder Bug-Hunt den nächsten Plan-Pass füttert — der Begriff stammt von Kieran Klaassen (every.to). Als Methodik zahlt er direkt auf agentic engineering-Praktiken ein: strukturiertes Memory statt verlorener Sessions.
Kieran Klaassen, every.to-Engineer hinter Cora, hat einen Loop beschrieben3: Plan, Work, Review, Compound. Im Plan zerlegen. Im Work bauen. Beim Review prüfen. Der entscheidende Schritt ist Compound, zurück in den Plan-Speicher. Jeder Bug-Hunt füttert die nächste Planung. Klaassen sagt, der Loop wird mit der Zeit besser, nicht schlechter.
Andrej Karpathy hat die andere Hälfte beschrieben4. „LLM-Wiki”, GitHub-Gist 2025: Dokumentation wird zum strukturierten Wissensspeicher für Agents. Nicht README. Nicht Confluence. Eine Vault, geschrieben für Modelle als Hauptleser, in der jeder Claim auf Code zeigt. Karpathy hat in derselben Periode den Begriff Context Engineering geprägt: nicht der Prompt zählt, sondern was vor dem Prompt im Kontext-Window steht. Das LLM-Wiki ist die Speicher-Schicht für genau diese Praxis.
Klaassen hatte den Loop, Karpathy den Store.
Aus zwei Welten wird eine
Ich habe flow.compound gebaut, um beides in einer Toolchain zu haben. Wie viel ein Agent auf einmal versteht ist begrenzt vom Kontext-Window — sein Arbeitsspeicher, in Karpathys LLM-als-OS-Bild4 der RAM. Mehr RAM ist nicht besser, und upgraden geht auch nicht. Was zählt ist welche Information er zur richtigen Zeit drin hat. Dafür braucht es vier Schichten Arbeitsspeicher, jede mit eigener Aufgabe: Code-Index (claude-context8, Milvus), Vault (Obsidian-Markdown plus DuckDB-Index), Session-Erinnerung (deja7, sqlite-vec), Pipeline-Memory (Forgejo plus Compound-Loop). Ich rufe sie nicht explizit auf, ich lade ihren Inhalt nicht in den Prompt. Sie reagieren implizit auf die Aufgabe.
Ich habe das durchprobiert, an einem realen Bug aus flow.raven, einer Transkript-Duplikation die quer durch die Pipeline lief. Erst Claude ohne Tools. Findet nichts, der Bug bleibt unsichtbar. Dann mit Tools verfügbar, aber ohne Anweisung die sagt wann er sie nehmen soll. Halluziniert einen Fix im falschen File und ist sich sicher dass er recht hat. Dann zwölf Reviewer-Agents parallel, jeder mit eigener Linse. Sie finden zusammen 28 False Positives und keinen Bug. Mehr Augen heißt nicht mehr Durchblick — sie addieren nur mehr selbstbewusste Fehl-Diagnosen. Die Reviewer, die mit ihrem kritischen Blick eigentlich Lücken und Code-Schwächen aufdecken sollten, werden in einer Auto-Pipeline so zum endlosen Token-Strudel.
Das beste kommt zum Schluss

Der Bench-Befund war eindeutig: zwölf Reviewer plus alle MCPs verfügbar, null MCP-Calls über den ganzen Lauf. Das ist keine Konfigurations-Schlampigkeit, das ist ein Architektur-Gap im Prompt-Layout. Statt zu raten habe ich vier Opus-Agents parallel als MoE auf die Frage „warum feuern die MCPs nicht” angesetzt — Anthropic-Engineering-Posts, GitHub-Issues, aktuelle arXiv-Papers. Sieben Paper kamen zurück, sechs offene Issues im anthropics/claude-code-Repo, eine konkrete Mechanik. Die Issues belegen aus verschiedenen Winkeln dieselbe Failure-Klasse: bindende Anweisungen werden unter Tool-Use-Load ignoriert, CLAUDE.md-Inhalte mid-conversation silently dropped12. Das ist kein flow.compound-Spezialfall, das ist breit gemessenes Verhalten im Tracker.
Der entscheidende Befund: Paipuru, „Navigation Paradox”, arXiv 2602.20048, Februar 20265. Eine bindende Routing-Checkliste am Anfang eines System-Prompts senkt die Tool-Adoption signifikant. Dieselbe Checkliste am Ende — getestete G3-Task-Klasse, Architecture-Discovery — springt von 85,7 auf 100 Prozent. Der Slot ganz hinten ist die einzige Position an der das Modell die Anweisung tatsächlich anwendet. Sun et al. zeigen flankierend6, dass ein Hidden-State-Classifier bereits vor dem Reasoning entscheidet ob ein Tool nötig ist — der End-Slot kippt genau diese Entscheidung. Das Paper ist drei Monate alt, das ist Prompt-Engineering-Frontier, nicht Folklore.
Aus dem Befund wurde der Patch. Dreißig Zeilen am Ende der CLAUDE.md, eine Routing-Anweisung die für jede Klasse von Frage genau ein Tool ansteuert: Code-Fragen an den Index, Vault-Fragen an die Doku, Strukturfragen an die DuckDB, Erinnerungs-Fragen an die Session-History. Selber Bug, selbe zwölf Agents, der gleiche Bench. Plötzlich rufen sie die Tools auf, die ganze Zeit über da waren und ignoriert wurden. False Positives gehen um über ein Drittel runter, die Kosten um 14 Prozent. Selbe Modelle, selbe Inputs, nur die Anweisung sitzt jetzt an der richtigen Stelle.
Paipuru hat das nur für Architecture-Discovery getestet. Meine Bug-Hunt-Bench läuft in einer anderen Task-Klasse, Symptom-Investigation. Der Sprung von 0 auf 23 MCP-Calls zeigt, dass der Mechanismus auch dort greift. Erweiterung des Befunds, nicht reine Replikation.
Eine Schicht trägt nicht. Zwei halten. Drei werden Verbund.
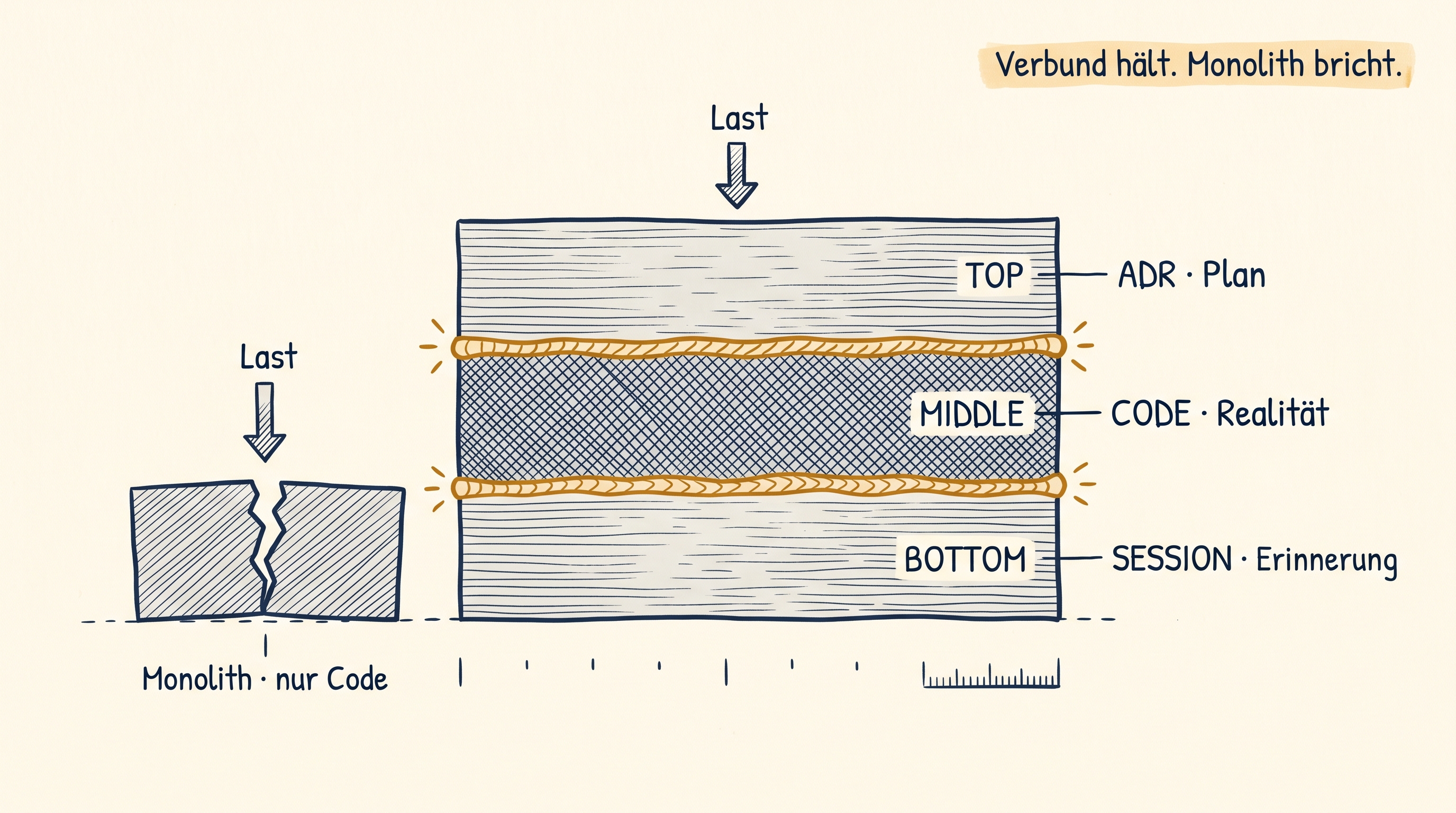
Wenn ein Agent nur eine Truth lesen kann, halluziniert er. Beispiel: er liest die ADR, baut gegen sie. Aber die ADR ist drei Wochen alt, der Code hat sich gedreht, und der Agent erfindet eine API die nicht mehr da ist. Die ADR weiß nichts vom Code, der Code weiß nichts vom Plan, und niemand merkt dass die beiden auseinander gelaufen sind.
Zwei Truths in unterschiedlicher Form reduzieren das Problem. ADR plus Code-Index, jede Doku-Citation pinned auf einen Commit. Drift wird messbar statt gefühlt. Der Agent sieht: hier sagt der Plan A, hier zeigt der Code B, die beiden weichen voneinander ab, das ist die Lücke.
Drei Truths machen das System brutal stark. Doku als Plan. Code als Realität. Sessions als Umsetzungs-Erinnerung. Jeder Schritt abgleichbar gegen jeden anderen. Wenn der Agent eine Behauptung aufstellt, kann er sie gegen alle drei Quellen prüfen bevor er sie ausgibt.
Wenn mehrere Layer Wahrheit übereinanderliegen, kann das System sich selbst entdriften. Das ist Kongruenz. Einfacher beschrieben: die Layer wirken wie ein Verbund, wie Kleber zwischen den Schichten. Ein Layer allein kann lügen. Zwei Layer halten sich gegenseitig. Drei Layer härten den Verbund aus. Drift in einer Schicht wird sichtbar, weil die anderen beiden ihn nicht mitmachen.
„Aber jetzt habe ich drei Layer zu pflegen”
Der Reflex: drei Layer heißt drei Mal Review-Aufwand. Falsch.
Der Vault ist Ground Truth. Er wird einmal sauber angelegt und ist von da an die Plan-Phase-Wahrheit. Alles fängt dort an. Code wird immer gegen den Vault gecheckt, nicht umgekehrt. Der Reviewer prüft nicht drei Layer gleich-gewichtig, sondern er prüft den Code gegen einen Plan der bereits konsolidiert ist.
Der eigentliche Aufwand fällt einmal an: den Vault sauber bauen. Danach reviewt jedes neue PR nicht mehr drei Wahrheiten, sondern eine: passt der Code zum Plan. Das ist weniger Aufwand als das Status-quo-Review, in dem jeder Reviewer den Plan jedes Mal neu im Kopf rekonstruiert.
Brownfield ist nicht das Problem. Brownfield ist die Mall.
Bei Greenfield muss ich erst Architektur-Entscheidungen treffen. Welche Auth, welche Datenbank, welche Tenant-Trennung, welcher Storage-Layer. Diese Entscheidungen bestimmen alles was danach kommt. Ein Grundstück braucht erst ein Fundament, bevor du irgendwas drauf bauen kannst, und ein starkes Fundament dauert.
Wenn das Fundament steht, kannst du darauf eine Mall bauen. Das Fundament trägt das Gebäude, das Gebäude trägt die Läden. Ein Feature ist ein Laden, kein neues Gebäude. Diese Woche ein Kinder-Spielparadies, nächste Woche eine Retro-Game-Halle mit Pinball und Pacman. Die Statik trägt beides. Du tauschst Läden aus, nicht das Gebäude und schon gar nicht das Fundament.
Agentic Engineering auf einem strukturierten Brownfield mit Truth-Cross-Check arbeitet genau so. Die schweren Entscheidungen sind einmal getroffen und in den drei Truths festgehalten. Der Agent muss nicht raten welche Auth-Library greift oder wie die Tenant-Trennung aussieht. Die Antwort steht in einer der drei Schichten, und die drei Schichten halten sich gegenseitig ehrlich.
4 Capabilities Agentic-Engineering-Gold
Code-Lookup über Repos hinweg
Ein realer Bug aus flow.raven: Transkript-Duplikation, irgendwo in der Pipeline. Drei Repos involviert: flow.raven, flow.raven-deployment, obsidian-knowledge-vault. Claude allein, mit nacktem grep im offenen Tree, fand nichts. Der Bug saß in einem Helper-Skript in flow.raven-deployment/scripts/, ich hatte das Repo gerade nicht offen.
Mit claude-context als MCP, einem Milvus-Index der alle drei Repos line-aware und hybrid (dense plus sparse) hält, war eine semantische Query genug: resolve_bucket function definition. Der Index zog vier relevante Code-Stellen gleichzeitig in den Kontext: die Definition, zwei Aufrufer im API-Layer, plus ein veralteter Test der die alte Signature noch annahm. Der Agent sah die ganze Kette auf einmal.
Das ist die echte Stärke und sie hat nichts mit Geschwindigkeit zu tun. Sieht der Agent nur eine Code-Stelle, halluziniert er den Rest. Sieht er die ganze Verkettung, schlägt er einen Fix vor der wirklich passt. Weniger Halluzinationen heißt weniger Review-Loops.
Claude allein: greppt im offenen Tree, sieht eine Stelle pro Query.
flow.compound: hybrider Index über alle Repos, semantische Query zieht mehrere relevante Stellen gleichzeitig in den Kontext.
Erinnerung über Sessions hinweg

Vor drei Wochen lief eine längere Recherche zu Freelancer-Pricing für ein Side-Projekt. Output-Faktor, Onboarding-Kosten, alles in einem Subagent-Thread berechnet, delegiertes Researcher-Setup. Letzten Donnerstag wollte ich die Zahlen wieder. Ich wusste nur: Math-Sache, irgendwann zwischen Mitte April und Anfang Mai.
Wir haben das gebencht, nicht geschätzt. grep über ~/.claude/projects/**/*.jsonl findet die Math nicht. Subagent-Threads werden in der Default-Erinnerung überhaupt nicht durchsucht, die delegierte Berechnung lag unsichtbar im Index. Volltextsuche nach „5000” oder „Faktor” liefert hunderte Treffer aus zusammenhanglosen Sessions, keiner davon die richtige.
Mit deja (sqlite-vec plus FTS5 mit RRF-Reranking, mein Fork hat Subagent-Indexing) lief eine semantische Suche über 181 000 Chunks aus 2693 Sessions, Subagent-Threads inklusive. Baseline auf demselben Task: 15 grep-Calls, 11 Minuten, nicht gefunden. Treatment: 2 Calls, 55 Sekunden, Math verbatim zurück inklusive Pricing-Calcs. include_subagents=True war der Unterschied — ohne den Flag liegt die Math im delegierten Subagent-Thread unsichtbar im Index.
/compact gibt es schon lange. Wenn der Kontext in einer langen Session voll wird, komprimiert Claude den Verlauf und du machst weiter. Das ist intra-Session. Was vorher nicht ging: eine neue Session die auf Wissen aus völlig unabhängigen alten Sessions zugreift. Das ist der Compound-Hebel. Jede Berechnung, jeder Bug-Hunt, jeder Recherche-Thread aus einem alten Projekt kann später wiederverwendet und mit neuem Kontext kombiniert werden. Trigger: „weißt du noch das mit dem Output-Faktor” und der relevante Kontext wird nachgeladen. Da liegt die Linie zwischen Prompt-Engineering und Context-Engineering. Beim Prompt-Engineering hätte ich den Kontext im Prompt explizit mitgegeben. Über Erinnern weiß der Agent implizit Bescheid, direkt über die Aufgabe.
Claude allein: keine Session-Memory zwischen
/clears.flow.compound: semantische Suche über 181 000 Chunks aus 2693 Sessions, Subagent-Threads inklusive, zwei Sekunden Antwortzeit.
Doku als Kraftstoff anstatt Mottenkiste
Mein Vault hat über 600 Pages. Konzepte, ADRs, Runbooks, Source-Pages, alles mit Wikilinks vernetzt. Jede Citation auf Code zeigt mit pinned_commit und Zeilen-Range, nicht auf HEAD.
ADRs sind „So soll die Architektur sein”. Sessions sind „So habe ich es tatsächlich umgesetzt”. Code ist „Was wirklich läuft”. Drei Snapshots der gleichen Realität, in drei verschiedenen Formen. Wenn alle drei übereinstimmen, ist die Sache stabil. Wenn eine driftet, ist die Lücke sichtbar.
Phase 11 vom Vault-Bootstrap: alle Pages gegen ihren gepinnten Commit gecheckt. Eine DuckDB-Query, drei-Way-Join über pages, code_citations und repo_pins, eine Sekunde Laufzeit, 2330 verifizierte Path-Hits, 36 Findings. Die schmerzhaftesten drei sind echte DOC-CODE-Contradictions: Ich hatte den Code in der Zwischenzeit refactored, Zeilen rausgenommen, die Datei ist geschrumpft, und meine Citation in der Doku zeigt jetzt ins Leere wie ein Wegweiser auf ein abgerissenes Haus. Dazu elf off-by-one in Diagramm-Files (trailing newline mitgezählt) und sieben Authoring-Bugs, die ich vorher nie gefunden hätte. Und am meisten tut die letzte Finding weh: zwei meiner eigenen ADRs widersprechen sich offen, tenant_id ist in einer UUID, in einer anderen TEXT. Ich hatte später eine andere Lösung identifiziert und vergessen, alle abhängigen Stellen mitzufixen. Das ist die Schwäche ohne flow.compound: du arbeitest auf einer Schicht, etwas verschiebt sich, und alle anderen Schichten — andere Code-Teile, ADR-Constraints, Tests — hängen mit dran, ohne dass du es siehst. Genau dafür ist semantische Suche, das Retrieval-Stück von RAG, gebaut: schnell finden, was zusammenhängt. Der Agent zieht die Treffer in seinen Kontext und generiert die Antwort daraus, statt aus seinem eigenen Gedächtnis (Trainingsdaten) zu raten.
Klassischer Markdown-Workflow findet das nicht. Confluence findet das nicht. Eine README findet das nicht. Verifizierbar nur, weil jede Page weiß, an welchem Commit sie pinned ist und welche Zeilen sie meint. Pinned Commits machen die ADRs abgleichbar mit dem Code und den Sessions. Das ist die zweite und dritte Truth, mechanisch.
ADR als Vertrag. Aus den drei Layern wird ein Vertrag. Eine ADR ist nicht mehr „so haben wir das mal gedacht”. Eine ADR sagt: dieser Code-Pfad muss so aussehen. Ich habe das an einem realen PR in flow.raven getestet. Ein Agent prüft die PR gegen alle akzeptierten ADRs und klassifiziert in drei Buckets: drift (Code widerspricht dem Plan), unklar (zweideutig), konform (passt). Das Ergebnis ist nicht „Findings die der Maintainer noch sortieren muss”. Das Ergebnis ist eine Vertrags-Prüfung, einlösbar zur PR-Zeit.
Claude allein: liest Docs als Prosa, kein Strukturwissen.
flow.compound: drei Truths abgleichbar, jeder Schritt verifizierbar.
Review Signal statt Noise

Derselbe Transkript-Duplikations-Bug, anderer Blickwinkel. Im Naiv-Setup zwölf Reviewer-Personas parallel, jede mit eigener Linse: Security, Performance, RLS, API-Design, und so weiter. Klingt nach „mehr Augen sehen mehr”. Resultat: 36 Raw-Findings, 28 davon False Positives, 78 Prozent Lärm. 5 von 12 Personas trafen das richtige File-Verzeichnis, keine einzige das tatsächliche Helper-Modul in media-api.
Im Production-Setup läuft nach den zwölf Personas ein Stage-5b-Validator. Ein unabhängiger Pass der jede Finding gegen Code, ADRs und vorherige Reviews validiert, mit Zugriff auf den Strukturindex. Resultat auf PR #668: 8 Raw-Findings, davon 4 valid, 4 gekillt, 2,55 USD. Der Validator-Reason für ein überlebendes Finding stand wörtlich in den Logs: „git blame confirms all three getattr lines new in 7a6ede7a”. Naive Setups haben diesen Schritt nicht. Sie posten oder droppen ungefiltert.
Der Mythos „mehr Agents gleich besseres Review” ist messbar falsch. Was stimmt: mehr Agents plus Validator-Pass mit Zugriff auf die drei Truths.
Compound Engineering gibt es nicht plug-and-play. Du musst die Reviewer um deine Architektur herum bauen. Bei mir bei flow.raven: ein LiveKit-Reviewer, weil LiveKit unsere Voice-Engine ist (La Suite Meet, ein Fork der französischen Regierung), ein Python-Reviewer, ein RLS-Reviewer für Postgres, weitere. Es gibt keinen Shortcut. Das ist der Preis. Wenn die paar Meter gegangen sind, ist der Hebel gigantisch.
Claude allein: ein Reviewer, eine Linse, blind. 12 Reviewer ohne Validator: 78 Prozent Noise.
flow.compound: 12 plus Validator, 50 Prozent Noise-Reduktion vor Push.
Was sich messbar ändert
| Capability | Claude allein | flow.compound | Effekt |
|---|---|---|---|
| Code-Lookup | grep im offenen Tree, eine Stelle pro Query | hybrid index, mehrere Code-Stellen pro Query | weniger Halluzinationen, kürzere Review-Loops |
| Erinnerung über Sessions | nichts überlebt /clear |
deja-Index, 181k Chunks, Subagents inklusive | compositional recall in 2 s |
| Doku-Drift | Prosa, nicht verifizierbar | drei Truths abgleichbar | 1,5 Prozent Drift messbar statt unsichtbar |
| Review-Noise | 12 Agents, 78 Prozent FPs, 10,26 USD/Run | + Validator mit Strukturindex, 2,55 USD/Run | Signal-Findings 8 → 4 valid, 0 Müll auf PR |
Wann es nicht funktioniert
- Greenfield. Erste Woche eines neuen Repos, du hast noch keinen Code, keine ADRs, keine Sessions. Der Compound-Loop hat nichts zum Compounden.
- Solo-Hack am Wochenende. Wenn das Projekt in drei Tagen wieder weg ist, lohnt sich die Vault-Pflege nicht. Schreib’s und schmeiß es weg.
- Deadline-Pressure unter 48 Stunden. Der Setup-Overhead ist real. Wenn du Freitag liefern musst, ist Dienstag zu spät zum Aufsetzen.
- Vault ohne Pflege. Die Vault muss curated bleiben. Wenn du nicht bereit bist, eine Page pro Bug-Hunt zu pflegen, hast du nach drei Monaten Müll im Store und der Compound-Loop verschlechtert sich.
- Team ohne Buy-in. Wenn nur du die Routing-Anweisung nutzt und die anderen ihren Agent „normal” fahren, hast du zwei Modes parallel und keine Konvergenz.
- Cross-Service-Bugs in symptom-mode. Bei dem Transkript-Duplikations-Bug saß der Helper in
media-api/*. Kein einziger der zwölf Reviewer hat das File angefasst — auch nicht das gepatchte Setup mit feuernden MCPs. Vier Expected-Files waren betroffen, alle Arme trafen genau eines. Symptom-Investigation über Service-Grenzen hinweg ist die offene Flanke. Der Validator catched, was die Personas vorgelegt haben — was niemand vorgelegt hat, bleibt unsichtbar.
Belege
Fünf Stellen an denen sich der Dev-Alltag verschiebt.
Der Transkript-Duplikations-Bug, der Test-Fall. Vier Setups probiert — kein einziges findet den Bug. Zwölf Reviewer mit allen MCPs verfügbar halluzinieren einen Fix ins falsche File. Nach dem Routing-Patch: vier valide Findings, korrekter Pfad, Bug fixbar im ersten Anlauf.
PR-Kommentare zum Durchklicken. Vorher 36 Findings, 28 davon Müll. Nachher 8 Findings, 4 davon Müll. Der Maintainer liest die Hälfte und keiner der Punkte ist erfunden.
Drift im Vault. 600 Pages hand-gepflegt, klassischer Markdown-Workflow, fühlt sich okay an. DuckDB-Query über die pinned Commits, eine Sekunde Laufzeit: 1,5 Prozent der Citations sind drifted, eine echte semantische Contradiction zwischen zwei ADRs (tenant_id als UUID hier, als TEXT da). Vorher unsichtbar, jetzt eine Zeile SQL.
Math-Thread von vor drei Wochen. grep über ~/.claude/projects/**/*.jsonl findet nichts — die Berechnung lag in einem delegierten Subagent-Thread, im Default-Index unsichtbar. deja mit Subagent-Indexing, ein semantischer Query, zwei Sekunden: vollständiger Thread mit den Pricing-Calcs zurück.
ADR gegen PR. Manueller Modus heißt: hoffen dass der Reviewer den Plan im Kopf hat. Als Vertrag: ein Agent klassifiziert die PR-Diffs in drift, unklar und konform — einlösbar zur PR-Zeit, nicht zur Maintainer-Zermürbung.
Wie gemessen wurde — Bench-Setups 1 bis 5. Vor dem Routing-Patch in vier Stufen probiert: 1 Reviewer ohne Tools (findet nichts, 0,07 USD), 1 Reviewer mit MCPs aber ohne Anweisung (halluziniert P0, 0,51 USD), 12 Reviewer parallel ohne Routing (28 FPs, 10,26 USD), 12 Reviewer plus MCPs ohne Routing-Patch (Personas ignorieren die MCPs weiter, 10,31 USD). Setup 5, dieselben 12 Reviewer mit 30 Zeilen Routing-Anweisung am Prompt-Ende: 23 MCP-Calls statt 0, False Positives minus 36 Prozent, Cost 8,91 USD statt 10,31 (minus 14 Prozent). Der Production-Smoke-Bench läuft mit Stage-5b-Validator obendrauf.
Ein Kommentar aus dem HN-Thread 48081469 fasst die Stimmung in der Branche zusammen9:
„I do not want to manage fleets of agents. I do not want to rediscover for the hundredth time that in fact all this time an agent took shortcuts.”
Der Anspruch am Anfang war: mein SaaS soll leichter werden je mehr ich baue. Was tatsächlich passiert wenn man Agents auf einen Brownfield loslässt, ist das Gegenteil — jedes Feature frisst mehr Review-Stunden als das davor, weil der Agent die existierende Codebase nicht mitsieht. Compound kehrt diese Richtung um. Der Bug von heute macht den Bug von nächster Woche billiger, weil die Concept-Page aus dem ersten Hunt beim nächsten Review-Pass schon im Kontext liegt. Die ADR von Freitag prüft die PR von Mittwoch, als Vertrag, nicht als Prosa. Der Drift-Sweep um 03:17 UTC findet die Lücke zwischen Plan und Code bevor sie eine Bug-Klasse wird.
Repariert hat sich Claude nicht. Repariert hat sich der Context drumherum. Wer das verstanden hat hört auf Agents zu sammeln und fängt an Memory zu bauen.
philflow.me · flow.compound