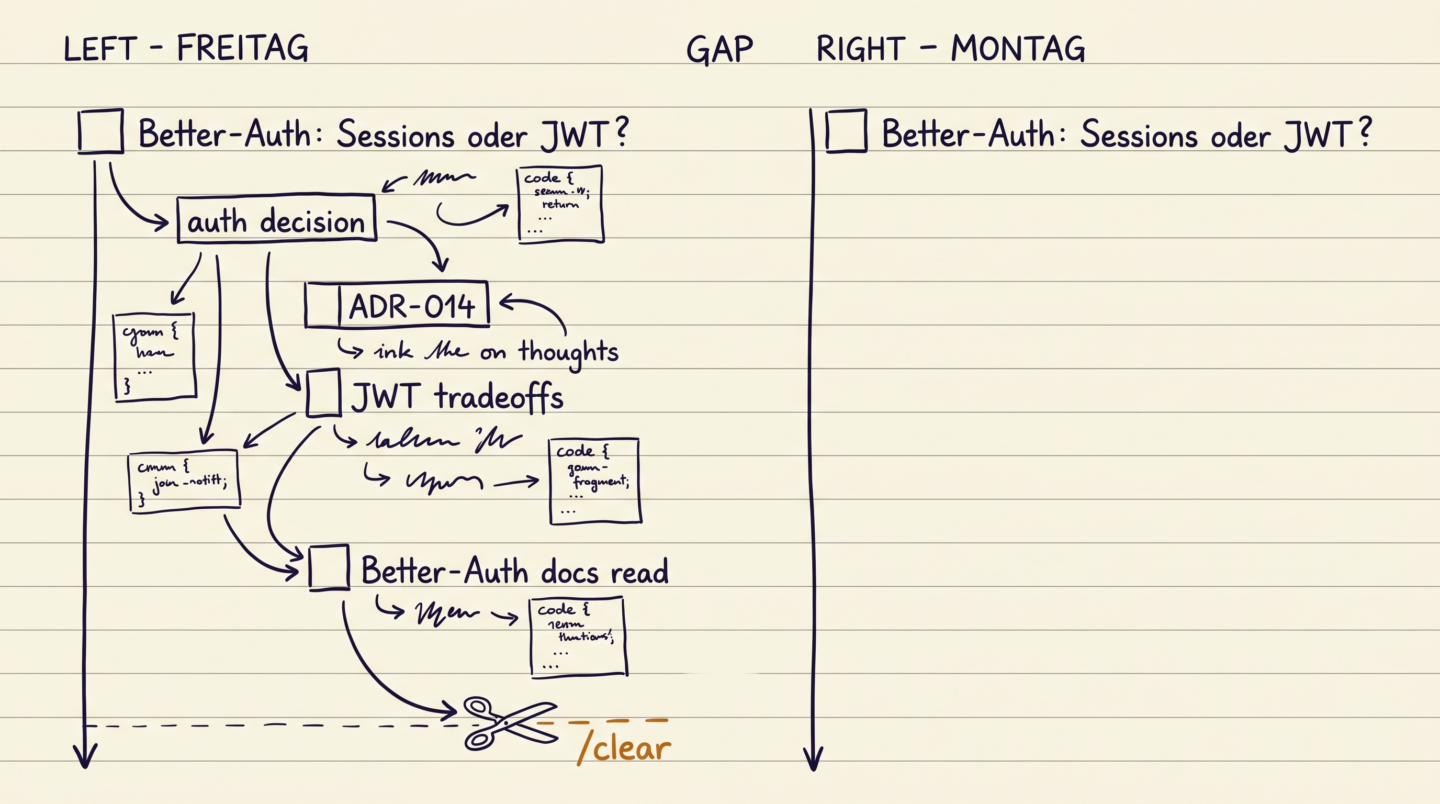
Three hours of sparring over auth architecture on Friday. We reached a decision, I wrote it up as an ADR, the code got merged. On Monday the same agent asks again whether we should go with Better-Auth using sessions or JWT. The decision was in the code, in an ADR, in a chat. None of it survived the /clear.
That is not annoying. It is like dementia, where you have the same conversation every few minutes.
"More time cleaning up than the agent saves you"
A comment on GitHub Issue #6601 in the anthropics/claude-code repo hits the nerve1:
"He is context damaged from the onset of fresh sessions, the very first response he is broken. You get a bit of the project to progress then spend twice as long repairing."
And from the r/ExperiencedDevs thread on AI-slop PRs, user SonOfSpades2:
"Multiple 5k+ line PR's that should be sub 100 lines. AI hallucinating external services, then mocking out the hallucinated external services."
I know both from my own practice. With my SaaS (three repos, a telephony pipeline), every PR review took longer than the development. The agent hallucinated a resolve_bucket() call that never existed. It invented a service endpoint and mocked it right away. Every refactor PR brought 5,000 lines because the agent had "cleaned up" the whole repo instead of touching the three files I meant.
My SaaS is supposed to get easier the more I build. In practice it is the opposite, and that is a problem.
For years the gospel has been: agents are great for greenfield. Fresh codebase, clean slate, the agent can build from zero. Brownfield is the other extreme: a grown codebase, ADRs that are no longer current, tests with assumptions, architecture that constrains other architecture. That's the mode almost all production code lives in. That's exactly where agents fall apart.
What is Compound Engineering
Compound Engineering is a loop of Plan, Work, Review, and Compound, in which every bug hunt feeds the next planning pass (the term comes from Kieran Klaassen, every.to). As a methodology it pays directly into agentic engineering practices: structured memory instead of lost sessions.
Kieran Klaassen, every.to engineer behind Cora, described a loop3: Plan, Work, Review, Compound. In Plan you decompose. In Work you build. In Review you check. The decisive step is Compound, back into the plan store. Every bug hunt feeds the next planning pass. Klaassen says the loop gets better over time, not worse.
Andrej Karpathy described the other half4. "LLM Wiki", GitHub Gist 2025: documentation becomes a structured knowledge store for agents. Not README. Not Confluence. A vault, written with models as the primary reader, where every claim points to code. Karpathy coined the term Context Engineering in the same period: it is not the prompt that matters, but what sits in the context window before the prompt. The LLM Wiki is the storage layer for exactly that practice.
Klaassen had the loop, Karpathy had the store.
Two worlds become one
I built flow.compound to have both in one toolchain. How much an agent can grasp at once is limited by the context window, its working memory, in Karpathy's LLM-as-OS image4, the RAM. More RAM is not better, and you cannot upgrade it either. What matters is which information is in there at the right time. For that you need four layers of working memory, each with its own role: code index (claude-context8, Milvus), vault (Obsidian-Markdown plus DuckDB index), session memory (deja7, sqlite-vec), pipeline memory (Forgejo plus Compound loop). I do not call them explicitly, I do not load their content into the prompt. They respond implicitly to the task.
I tested this on a real bug from flow.raven: a transcript duplication that ran through the whole pipeline. First, Claude without tools. Finds nothing, the bug stays invisible. Then with tools available, but no instruction saying when to use them. Hallucinates a fix into the wrong file and is certain he is right. Then twelve reviewer agents in parallel, each with its own lens. Together they find 28 false positives and zero bugs. More eyes does not mean more insight; it just adds more confidently-delivered wrong diagnoses. The reviewers who were supposed to catch gaps and code weaknesses with their critical lens instead become an endless token drain in an automated pipeline.
The best part comes last

The bench finding was unambiguous: twelve reviewers plus all MCPs available, zero MCP calls across the entire run. That is not a configuration slip; that is an architectural gap in the prompt layout. Instead of guessing, I deployed four Opus agents in parallel as a MoE on the question why the MCPs were not firing: Anthropic engineering posts, GitHub issues, recent arXiv papers. Seven papers came back, six open issues in the anthropics/claude-code repo, one concrete mechanism. The issues document from different angles the same failure class: binding instructions are ignored under tool-use load, CLAUDE.md content silently dropped mid-conversation12. That is not a flow.compound edge case; it is broadly measured behavior in the tracker.
The decisive finding: Paipuru, "Navigation Paradox", arXiv 2602.20048, February 20265. A binding routing checklist at the start of a system prompt significantly lowers tool adoption. The same checklist at the end, tested G3 task class, Architecture-Discovery, jumps from 85.7 to 100 percent. The very last slot is the only position where the model actually applies the instruction. Sun et al. show alongside6 that a hidden-state classifier decides whether a tool is needed before reasoning even begins; the end slot flips exactly that decision. The paper is three months old; that is prompt-engineering frontier, not folklore.
From the finding came the patch. Thirty lines at the end of CLAUDE.md, a routing directive that steers each question class to exactly one tool: code questions to the index, vault questions to the docs, structure questions to DuckDB, memory questions to session history. Same bug, same twelve agents, the same bench. Suddenly they call the tools that were there the whole time, being ignored. False positives drop by over a third, cost by 14 percent. Same models, same inputs; the instruction is just sitting in the right place now.
Paipuru only tested this for Architecture-Discovery. My bug-hunt bench runs in a different task class: symptom investigation. The jump from 0 to 23 MCP calls shows the mechanism holds there too. An extension of the finding, not a pure replication.
One layer does not hold. Two do. Three become a composite.
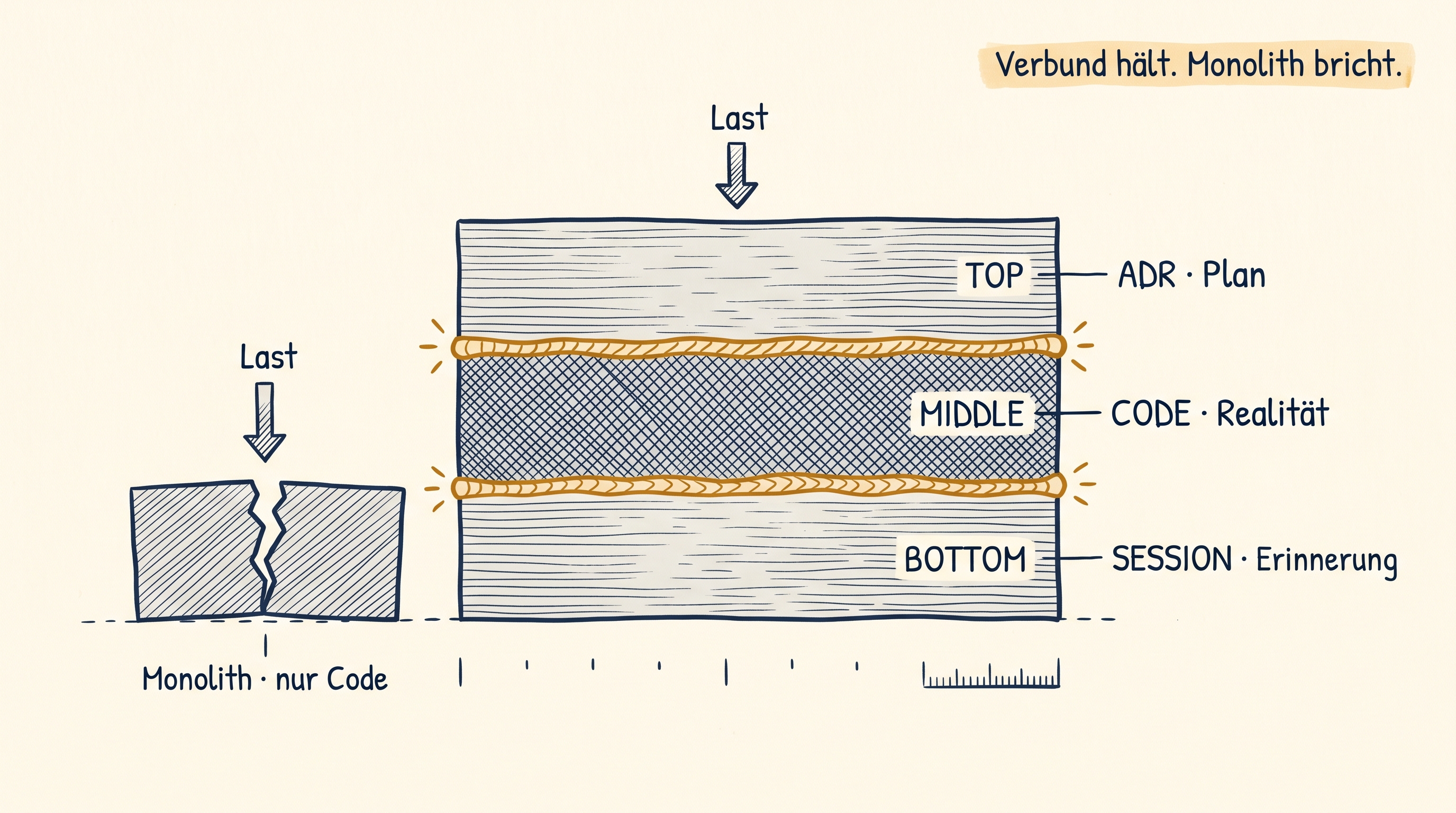
When an agent can only read one truth, it hallucinates. Example: it reads the ADR and builds against it. But the ADR is three weeks old, the code has shifted, and the agent invents an API that no longer exists. The ADR knows nothing about the code, the code knows nothing about the plan, and nobody notices that the two have drifted apart.
Two truths in different forms reduce the problem. ADR plus code index, every doc citation pinned to a commit. Drift becomes measurable instead of felt. The agent sees: here the plan says A, here the code shows B, the two diverge. That is the gap.
Three truths make the system brutally strong. Docs as plan. Code as reality. Sessions as implementation memory. Every step crosscheckable against every other. When the agent makes a claim, it can verify it against all three sources before outputting it.
When multiple layers of truth lie on top of each other, the system can self-de-drift. That's congruence. Simply put: the layers work like a composite, like glue between sheets. One layer alone can lie. Two layers keep each other honest. Three layers cure the composite. Drift in one layer becomes visible because the other two do not follow it.
"But now I have three layers to maintain"
The reflex: three layers means three times the review overhead. Wrong.
The vault is ground truth. It's built cleanly once and from then on is the plan-phase truth. Everything starts there. Code is always checked against the vault, not the other way around. The reviewer does not weigh three layers equally; he checks the code against a plan that is already consolidated.
The real effort comes once: building the vault cleanly. After that, each new PR does not review three truths, just one: does the code match the plan. That's less work than the status-quo review, where every reviewer reconstructs the plan in their head each time.
Brownfield is not the problem. Brownfield is the mall.
With greenfield I have to make architectural decisions first. Which auth, which database, which tenant isolation, which storage layer. Those decisions determine everything that follows. A plot of land needs a foundation before you can build anything on it, and a solid foundation takes time.
Once the foundation is there, you can build a mall on it. The foundation carries the building, the building carries the shops. A feature is a shop, not a new building. This week a children's play paradise, next week a retro gaming hall with pinball and Pac-Man. The structure carries both. You swap shops, not the building, and certainly not the foundation.
Agentic engineering on a structured brownfield with truth cross-checks works exactly like that. The heavy decisions have been made once and are recorded in the three truths. The agent does not have to guess which auth library is in play or how tenant isolation is structured. The answer is in one of the three layers, and the three layers keep each other honest.
4 Capabilities of Agentic-Engineering-Gold
Cross-repo code lookup
A real bug from flow.raven: transcript duplication, somewhere in the pipeline. Three repos involved: flow.raven, flow.raven-deployment, obsidian-knowledge-vault. Claude alone, with bare grep in the open tree, found nothing. The bug sat in a helper script in flow.raven-deployment/scripts/; that repo was not open at the time.
With claude-context as an MCP (a Milvus index holding all three repos, line-aware and hybrid, dense plus sparse), a single semantic query was enough: resolve_bucket function definition. The index pulled four relevant code locations into context simultaneously: the definition, two callers in the API layer, plus a stale test that still assumed the old signature. The agent saw the entire chain at once.
That's the real strength, and it has nothing to do with speed. When the agent sees only one code location, it hallucinates the rest. When it sees the full chain, it proposes a fix that actually fits. Fewer hallucinations means shorter review loops.
Claude alone: greps in the open tree, sees one location per query.
flow.compound: hybrid index across all repos, semantic query pulls multiple relevant locations into context simultaneously.
Memory across sessions

Three weeks ago there was an extended research session on freelancer pricing for a side project. Output factor, onboarding costs, everything calculated in a subagent thread, delegated researcher setup. Last Thursday I needed the numbers again. All I knew: math thing, sometime between mid-April and early May.
We benched this, did not estimate. grep over ~/.claude/projects/**/*.jsonl does not find the math. Subagent threads are not searched at all in the default memory; the delegated calculation was invisible in the index. Full-text search for "5000" or "factor" returns hundreds of hits from unrelated sessions, none of them the right one.
With deja (sqlite-vec plus FTS5 with RRF reranking, my fork has subagent indexing), a semantic search over 181,000 chunks from 2,693 sessions, subagent threads included. Baseline on the same task: 15 grep calls, 11 minutes, not found. Treatment: 2 calls, 55 seconds, math returned verbatim including pricing calculations. include_subagents=True was the difference; without that flag the math sits invisible in the delegated subagent thread in the index.
/compact has existed for a while. When context fills up in a long session, Claude compresses the history and you keep going. That's intra-session. What was not possible before: a new session that accesses knowledge from entirely independent old sessions. That's the Compound lever. Every calculation, every bug hunt, every research thread from an old project can be reused later and combined with new context. Trigger: "do you remember the output-factor thing" and the relevant context loads in. That's where the line between prompt engineering and Context Engineering lies. With prompt engineering I would have explicitly included the context in the prompt. With memory, the agent knows implicitly, directly through the task.
Claude alone: no session memory between
/clears.flow.compound: semantic search over 181,000 chunks from 2,693 sessions, subagent threads included, two-second response time.
Docs as fuel, not a dusty attic
My vault has over 600 pages. Concepts, ADRs, runbooks, source pages, all interlinked with wikilinks. Every code citation points with pinned_commit and line range, not at HEAD.
ADRs are "how the architecture should be". Sessions are "how I actually implemented it". Code is "what actually runs". Three snapshots of the same reality in three different forms. When all three agree, things are stable. When one drifts, the gap is visible.
Phase 11 of the vault bootstrap: all pages checked against their pinned commit. A DuckDB query, three-way join over pages, code_citations, and repo_pins, one second runtime, 2,330 verified path hits, 36 findings. The three most painful are real DOC-CODE contradictions: I had refactored the code in the meantime, removed lines, the file shrank, and my citation in the docs now points into the void like a signpost to a demolished building. Plus eleven off-by-ones in diagram files (trailing newline counted) and seven authoring bugs I would never have found before. And the last finding hurts most: two of my own ADRs openly contradict each other: tenant_id is UUID in one, TEXT in another. I had later identified a different solution and forgotten to update all the dependent locations. That's the weakness without flow.compound: you work on one layer, something shifts, and all the other layers (other code parts, ADR constraints, tests) drag along, invisibly. That's exactly what semantic search, the retrieval piece of RAG, is built for: fast discovery of what's connected. The agent pulls the hits into its context and generates the answer from them, instead of guessing from its own memory (training data).
Classic markdown workflow does not catch that. Confluence does not catch it. A README does not catch it. Verifiable only because every page knows which commit it is pinned to and which lines it means. Pinned commits make ADRs crosscheckable against code and sessions. That's the second and third truth, mechanically.
ADR as contract. From the three layers emerges a contract. An ADR is no longer "what we thought at the time". An ADR says: this code path must look like this. I tested this on a real PR in flow.raven. An agent checks the PR against all accepted ADRs and classifies into three buckets: drift (code contradicts the plan), unclear (ambiguous), conform (fits). The result is not "findings the maintainer still has to sort". The result is a contract check, redeemable at PR time.
Claude alone: reads docs as prose, no structural knowledge.
flow.compound: three truths crosscheckable, every step verifiable.
Review signal instead of noise

Same transcript-duplication bug, different angle. In the naive setup: twelve reviewer personas in parallel, each with its own lens: security, performance, RLS, API design, and so on. Sounds like "more eyes see more". Result: 36 raw findings, 28 of them false positives, 78 percent noise. 5 of 12 personas hit the right file directory, not one hit the actual helper module in media-api.
In the production setup, after the twelve personas, a Stage-5b validator runs. An independent pass that validates every finding against code, ADRs, and previous reviews, with access to the structural index. Result on PR #668: 8 raw findings, 4 valid, 4 killed, $2.55. The validator reason for a surviving finding was quoted verbatim in the logs: "git blame confirms all three getattr lines new in 7a6ede7a". Naive setups do not have this step. They post or drop unfiltered.
The myth "more agents equals better review" is measurably false. What's true: more agents plus a validator pass with access to the three truths.
Compound Engineering is not plug-and-play. You have to build the reviewers around your architecture. For me with flow.raven: a LiveKit reviewer because LiveKit is our voice engine (La Suite Meet, a fork from the French government), a Python reviewer, an RLS reviewer for Postgres, others. There's no shortcut. That's the price. Once those few steps are taken, the leverage is enormous.
Claude alone: one reviewer, one lens, blind. 12 reviewers without validator: 78 percent noise.
flow.compound: 12 plus validator, 50 percent noise reduction before push.
What changes measurably
| Capability | Claude alone | flow.compound | Effect |
|---|---|---|---|
| Code lookup | grep in open tree, one location per query | hybrid index, multiple code locations per query | fewer hallucinations, shorter review loops |
| Memory across sessions | nothing survives /clear |
deja index, 181k chunks, subagents included | compositional recall in 2 s |
| Doc drift | prose, not verifiable | three truths crosscheckable | 1.5 percent drift measurable instead of invisible |
| Review noise | 12 agents, 78 percent FPs, $10.26/run | + validator with structural index, $2.55/run | signal findings 8 → 4 valid, 0 garbage on PR |
When it does not work
- Greenfield. First week of a new repo: no code yet, no ADRs, no sessions. The Compound loop has nothing to compound.
- Solo hack over a weekend. If the project is gone in three days, vault maintenance does not pay. Write it and throw it away.
- Deadline pressure under 48 hours. The setup overhead is real. If you have to ship Friday, Tuesday is too late to set this up.
- Vault without upkeep. The vault has to stay curated. If you are not willing to maintain one page per bug hunt, you will have garbage in the store after three months and the Compound loop will degrade.
- Team without buy-in. If only you use the routing directive and everyone else runs their agent "normally", you have two modes in parallel and no convergence.
- Cross-service bugs in symptom mode. With the transcript-duplication bug, the helper sat in
media-api/*. Not one of the twelve reviewers touched that file, even in the patched setup with firing MCPs. Four expected files were affected; every arm hit exactly one. Symptom investigation across service boundaries is the open flank. The validator catches what the personas submitted; what nobody submitted stays invisible.
Evidence
Five places where dev life shifts.
The transcript-duplication bug, the test case. Four setups tried: not one finds the bug. Twelve reviewers with all MCPs available hallucinate a fix into the wrong file. After the routing patch: four valid findings, correct path, bug fixable on the first attempt.
PR comments to click through. Before: 36 findings, 28 of them garbage. After: 8 findings, 4 of them garbage. The maintainer reads half, and none of the points are invented.
Drift in the vault. 600 pages hand-curated, classic markdown workflow, feels fine. DuckDB query over the pinned commits, one second runtime: 1.5 percent of citations are drifted, a real semantic contradiction between two ADRs (tenant_id as UUID here, as TEXT there). Previously invisible, now one line of SQL.
Math thread from three weeks ago. grep over ~/.claude/projects/**/*.jsonl finds nothing; the calculation sat in a delegated subagent thread, invisible in the default index. deja with subagent indexing, one semantic query, two seconds: full thread with pricing calculations returned.
ADR against PR. Manual mode means: hope the reviewer has the plan in their head. As a contract: an agent classifies the PR diffs into drift, unclear, and conform, redeemable at PR time, not at maintainer-exhaustion time.
How it was measured, bench setups 1 to 5. Four stages tested before the routing patch: 1 reviewer without tools (finds nothing, $0.07), 1 reviewer with MCPs but no instruction (hallucinates P0, $0.51), 12 reviewers parallel without routing (28 FPs, $10.26), 12 reviewers plus MCPs without routing patch (personas keep ignoring MCPs, $10.31). Setup 5, same 12 reviewers with 30 lines of routing directive at the prompt end: 23 MCP calls instead of 0, false positives down 36 percent, cost $8.91 instead of $10.31 (−14 percent). The production smoke bench runs with the Stage-5b validator on top.
A comment from HN thread 48081469 captures the mood in the industry9:
"I do not want to manage fleets of agents. I do not want to rediscover for the hundredth time that in fact all this time an agent took shortcuts."
The original goal was: my SaaS should get easier the more I build. What actually happens when you unleash agents on a brownfield is the opposite: every feature consumes more review hours than the one before, because the agent cannot see the existing codebase. Compound reverses that direction. Today's bug makes next week's bug cheaper, because the concept page from the first hunt is already in context on the next review pass. Friday's ADR checks Wednesday's PR as a contract, not as prose. The 03:17 UTC drift sweep finds the gap between plan and code before it becomes a bug class.
Claude did not fix himself. What got fixed was the context around him. Once you understand that, you stop collecting agents and start building memory.
philflow.me · flow.compound